London is a significant destination for many people at various lifestages. One particularly popular inflow is university graduates looking for a place to live as they start their first career-minded job in the capital – coming from the other 100 or so universities in the UK outside London, or from Europe or elsewhere.
It is often a rush to find somewhere to live, as it’s hard to get time off to search for houses when starting on a graduate career. London is also a very expensive place if you do not have an established income and have not yet received your first pay cheque!
So, many people start in the capital by sharing with friends, fellow interns, or other people in a similar situation. There is a significant geographic clustering in where these people live, and they are quite easy to spot in a couple of Census tables. They likely live in places which are not right in the centre of the city (too expensive) but which are well connected to the City and the West End (the major sources of graduate employers) by tube or other transport. Above all, they are likely places with an established nightlife, with bars and clubs, to ease the transition from university life to a professional career, and help people find their feet.
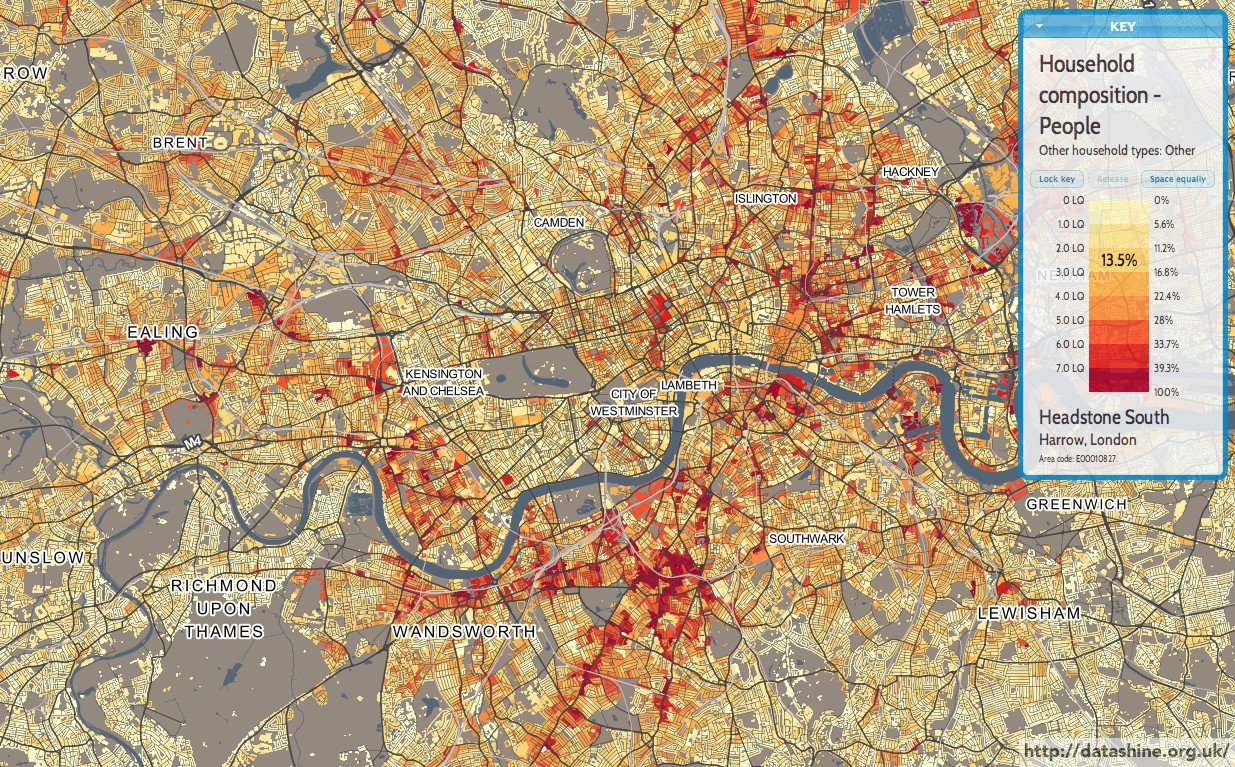
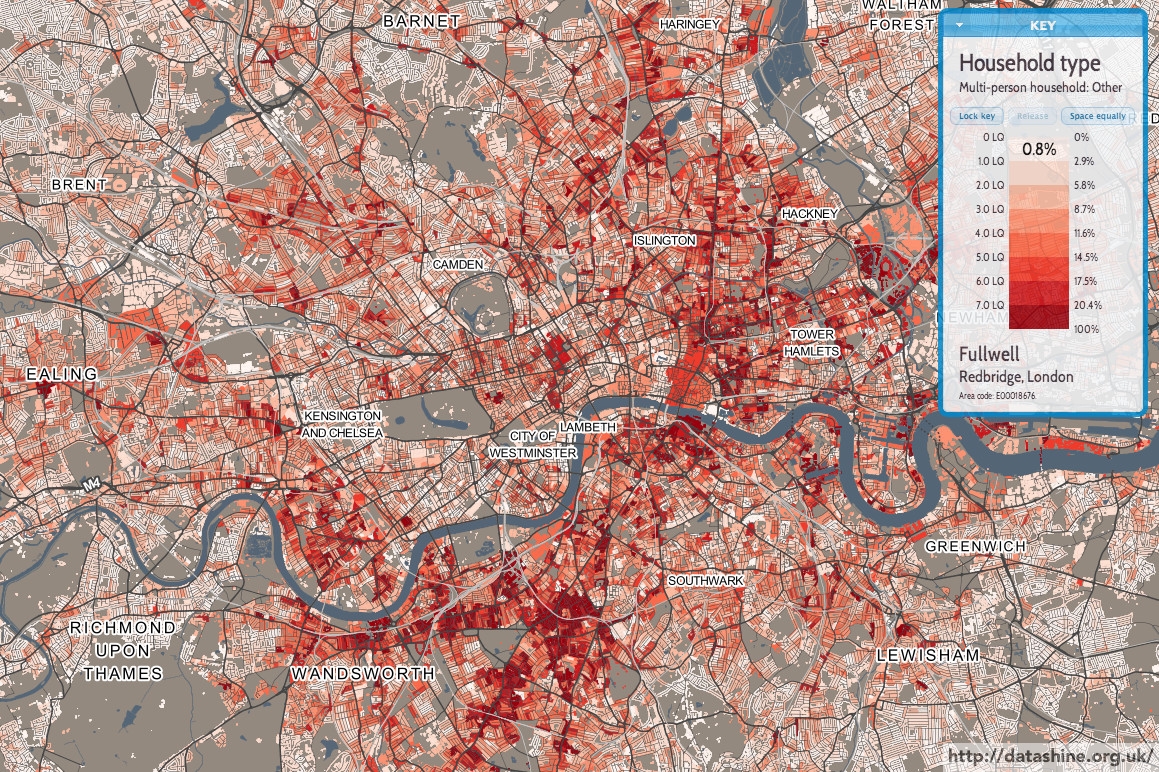
Above is a map showing multi-person households where not all those in the household are students or married/cohabiting. The highest values, where over 20% of households in an area fall into this category, are shown as dark red. In some places, such as parts of Clapham, Whitechapel and Hackney Wick, the figure is over 40%. Other popular areas are Fulham, Balham, Shoreditch and Dalston. All places with a high number of bars and a mix of nightlife and residential blocks.
By contrast, further out areas – Bromley, Bexley, Enfield, Kew – see very low percentages. There is also a noticeable dip in Kensington & Chelsea – nice and central, but almost all places here are likely far too expensive for the majority of those just starting out in London.
You can see an interactive version of the map here.
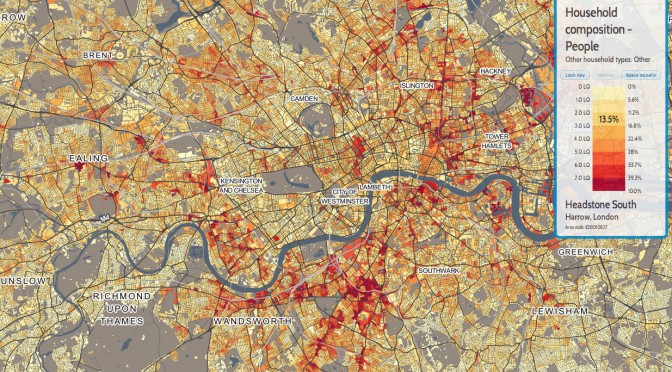
There are some similar tables: looking at Household Composition and excluding one-person and one-family households, as well as those with dependent children, or entirely composed of students or over 65s, look like this: